关于语音转文字这个话题,阿虚上一次介绍已经是几年之前了
除了不少工具失效,如今又有了新的工具出现,再加上经常被大家问到,且阿虚自己也有这个需求(经常需要帮我妈转换视频成文本她方便学习),所以今天就打算再来替大家研究一下2023年的语音转文字方案

虽说是语音转文字,但实际上视频转文字也可以划到同一个问题场景之下——毕竟随便就能找到软件把视频转为音频

阿虚很早之前就推荐过音视频格式转换软件(?点击即可查看)
除此之外,视频生成字幕其实也可以归属于同一类问题(带时间轴),不过这个问题更多应该是视频制作者才会需要,阿虚之前也有专门写过(?点击即可查看),这里就不赘述了
阿虚这篇文章还是就准备再来重新介绍一下2023年值得推荐的语音识别工具(按提供服务的厂商进行介绍)

最重要的各平台识别质量对比,请见文末
林宥嘉 – 向前走 (Live),阿虚同学,5分钟
1
网易
1.1
网易见外(网页)
地址:https://sight.youdao.com/
网易见外是网易人工智能事业部旗下的 AI 视频翻译产品,阿虚印象中好像是国内最早一批上线的此类服务了
而天地良心的,从2017年9月上线到现在,这个平台一直都是免费的!虽然这期间有过平台将下线的流言,但事实上直到如今依旧可以正常使用

你只需要登录你的网易账号,就可以享受这个平台诸多的「AI 智能转写」服务,从最开始主打的视频翻译,到如今已经支持视频转写、字幕翻译、文档翻译、语音翻译、语音转写、会议同传、图片翻译整整8大功能了
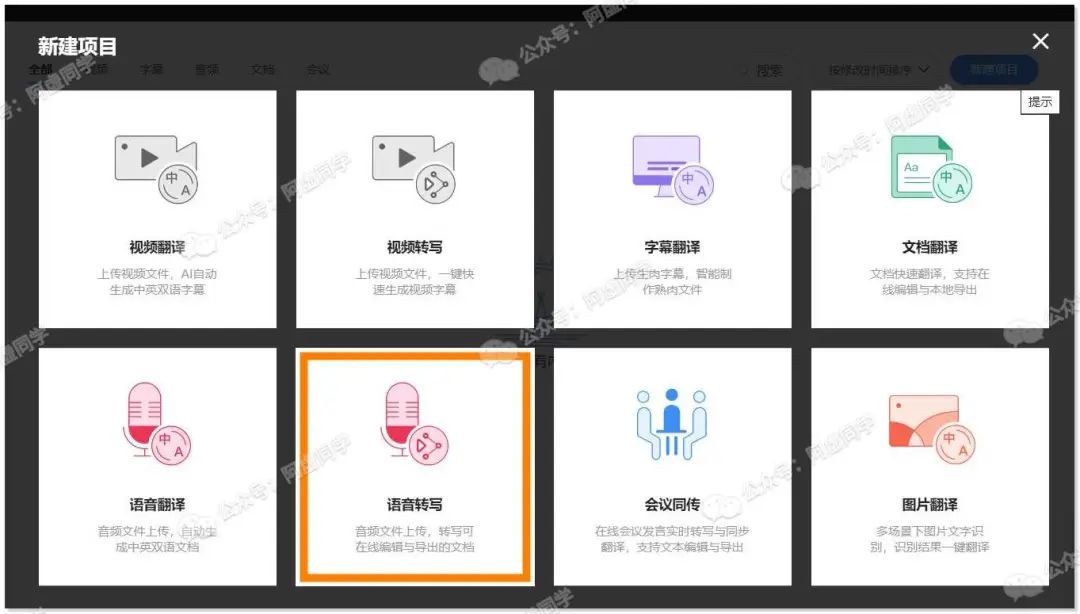
如果我们需要将视频或者音频转成文字,那么需要使用的是「语音转写」这个功能
单次仅允许<500M,mp3、wav、aac 格式的音频文件,支持中文或者英文,另外据悉每天上传的音频不能超过 2 小时

阿虚测试了一个4分多钟的音频,大概不到1分钟就转写好了,转写好之后可以在线预览:随着音频播放会加粗高亮显示实际转写出来对应的哪一句
如果你发现整个文档有某些词都统一转写错了,还可以点击顶部进行「词汇替换」,同时这里也可以进行「语气词过滤」
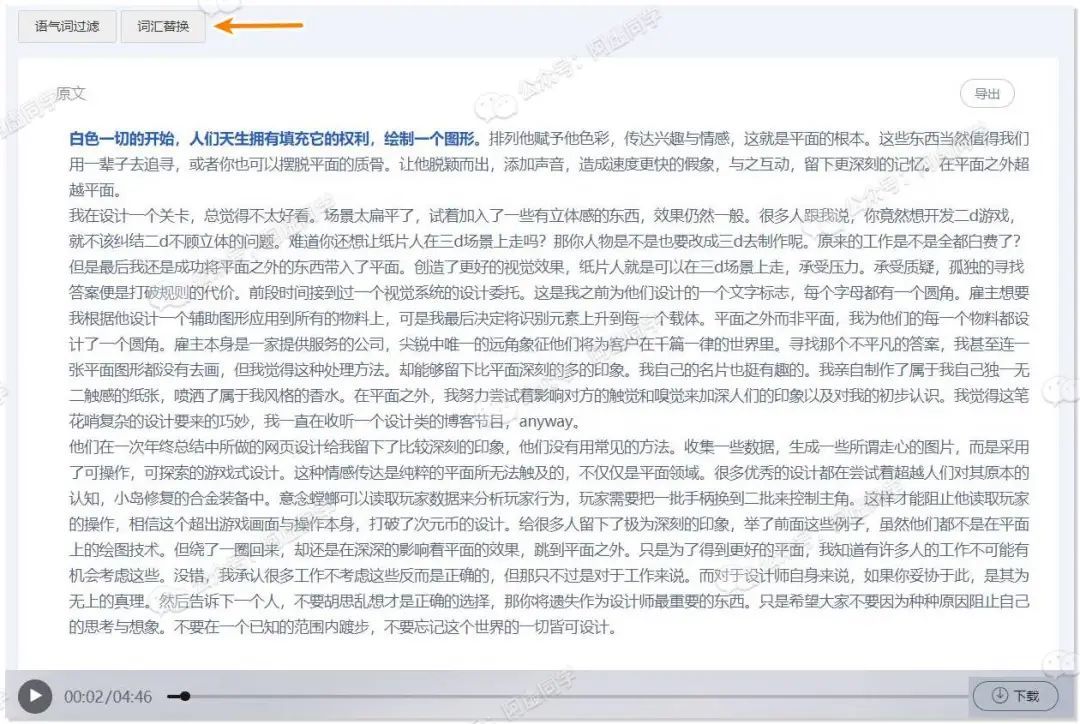
确认没问题之后最后可以在右上角导出为 Word 文件,使用起来可以说是相当便捷简单的
1.2
有道云笔记(安卓/iOS)
地址:https://note.youdao.com/
这里还不得不说网易其实在语音识别这块做的挺良心,除了有完全免费的网易见外,旗下的有道云笔记的实时语音识别竟也是完全免费的

如果你需要边录边转写,那有道云笔记或许就是一个非常不错的选择,只需要登录有道云笔记,点击语音速记 » 再点击转文字就行了
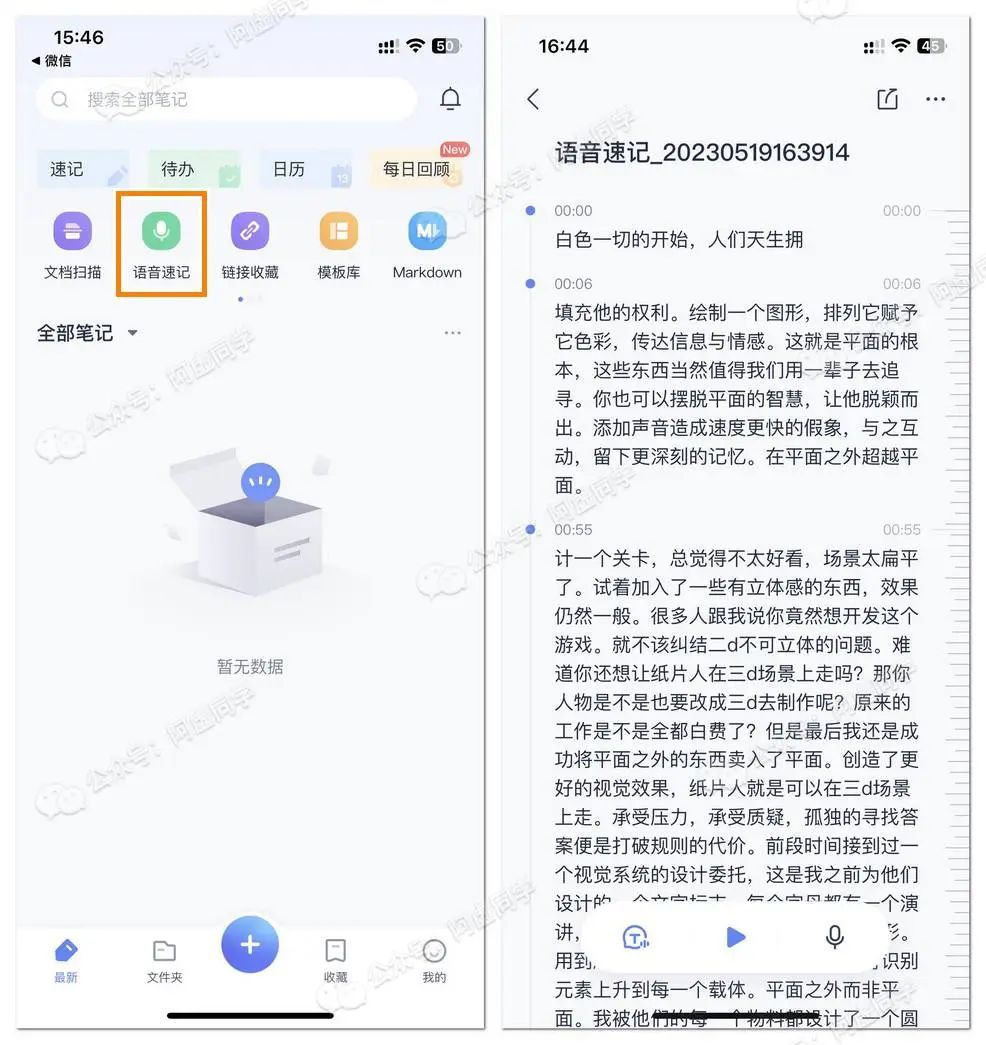
识别完成之后,可以把识别结果导出为存文字笔记(存文字,基本上和 TXT 差不多)
2
腾讯
2.1
腾讯云语音识别(网页/微信小程序)
地址:https://cloud.tencent.com/product/asr
除了网易,腾讯其实也提供了语音识别体验服务,打开上述链接点「立即使用」,登录腾讯云账号即可

目前的话免费额度还是相当良心的,不仅支持上传录音文件,更是支持实时语音识别,对个人偶尔使用我觉得这个每月额度完全足够(实在不够你可以弄多个账号嘛)

计费规则可能会变动,最新计费说明见官方文档:https://cloud.tencent.com/document/product/1093/35686
找到功能体验,我们就能上传文件进行识别了,目前识别语言支持普通话、粤语、上海话、英语、日语,并且还有非常强大的一点是支持分离说话人,即如果音频中有多个人说话,将会自动区别开!


具体识别结果要不要时间戳可以自行选择,导出的识别结果是 txt 文件
在网页端扫描二维码之后,即可在手机端的微信小程序进行实时语音识别(每月5小时)

2.2
字幕组机翻小助手 Tern(Win/Mac)
Github地址:https://github.com/1c7/Translate-Subtitle-File
如果你访问Github困难,建议了解《2022 Github加速访问教程》
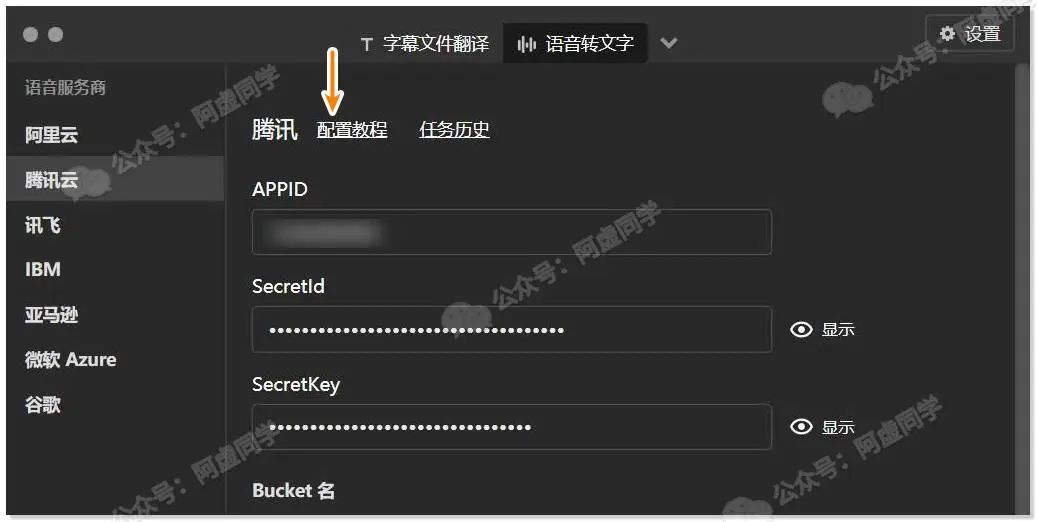
除了上述从网页端使用腾讯云语音识别,我们也可以利用字幕组机翻小助手这款开源软件来进行调用,使用没啥难度,把文件拖进去点击开始识别即可


当然是用前需要进行比较繁琐的参数配置,这里的话由于软件内有提供详细的步骤,阿虚就不在此赘述了
其实从下图可以看到我们还可以配置阿里云、讯飞、IBM等服务商的语音识别服务,但除了阿里云、腾讯、IBM 其他都是收费才能使用,并且 IBM 注册配置稍显麻烦,中文识别肯定没有国内服务商做的好,阿虚也不是很推荐去折腾了

3
阿里巴巴
3.1
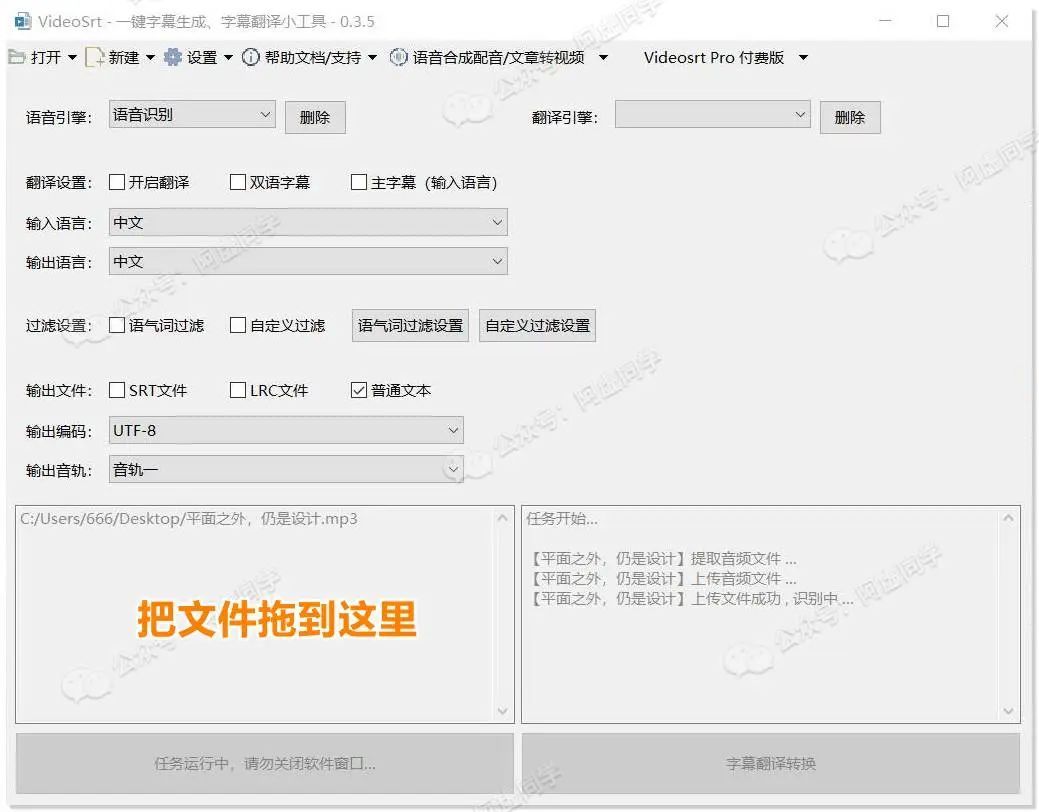
Videosrt(Win)
Github地址:https://github.com/wxbool/video-srt-windows
如果你访问Github困难,建议了解《2022 Github加速访问教程》
VideoSrt 这款开源免费的软件,其实也在之前视频免费生成字幕方案那期文章就介绍过,通过这款软件我们可以几乎免费使用阿里云的语音识别引擎,个人每天有 2 小时的语音识别免费额度


计费规则可能会变动,最新计费说明见官方文档:https://help.aliyun.com/document_detail/207373.html
只不过是用这款软件的步骤比较繁琐,需要我们手动先去申请阿里云的相关 API,配置到软件之后才能使用
具体 API 的申请&配置,作者做了长达10分钟的超详细视频教程,阿虚便不在此赘述了:https://www.yuque.com/viggo-t7cdi/videosrt/em4n10

▲扫码即可查看
总之等你花大把时间把OSS、语音识别引擎的参数都配置好之后,就可以轻松使用软件了

4
字节跳动
4.1
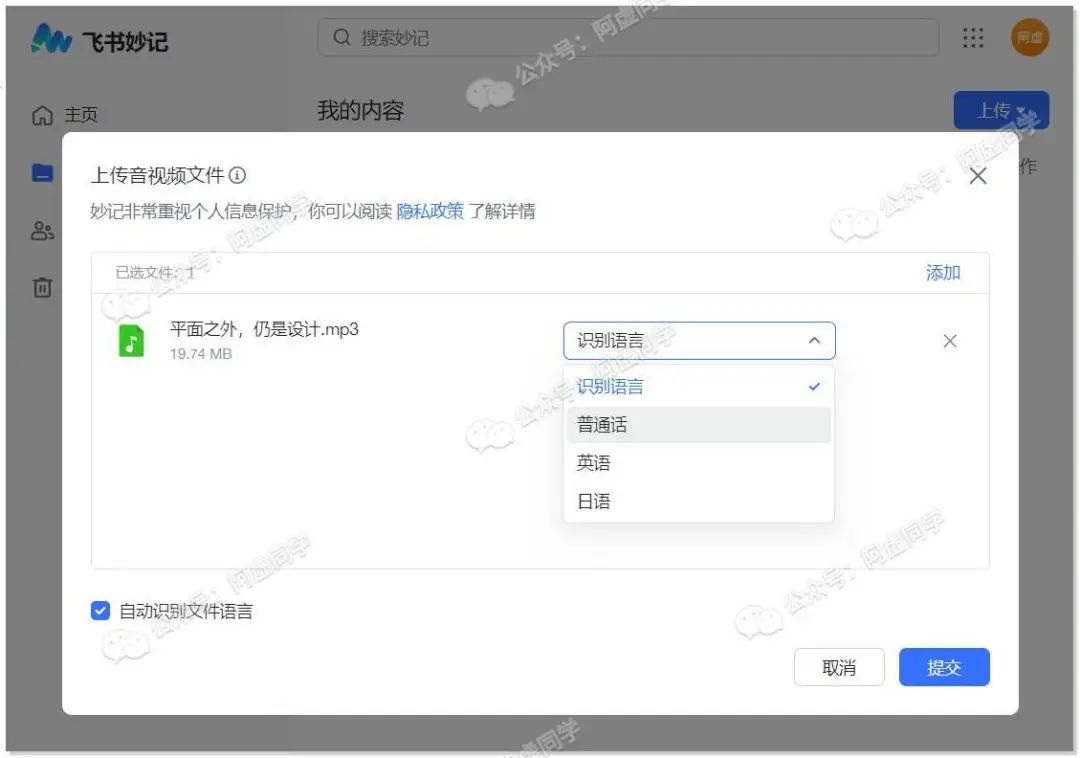
飞书妙记(全平台)
地址:https://www.feishu.cn/product/minutes
飞书妙记则是这几年新晋互联网巨头字节跳动(抖音的公司)旗下产品,目前也是非常良心的完全免费


使用方法异常简单,注册登陆后,直接上传音频或者视频就能进行识别转换了,目前支持普通话、英语、日语
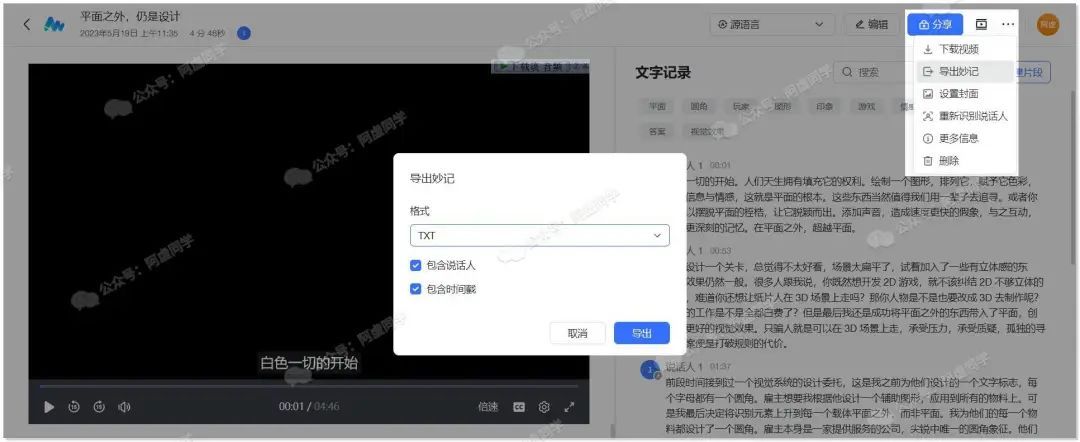
支持识别不同说话人,同时能自动添加标点符号和章节分段,识别完成之后可在网页有上角导出为 TXT 或 SRT 格式
除了网页端,在飞书APP上搜索安装飞书妙记应用之后,也可以快速在移动端录制音频进行识别(在录制时就会实时展示转写结果)
4.2
剪映(Win/安卓/iOS)
然后说一下在之前视频免费生成字幕方案那期文章里介绍过的剪映——这个其实也是抖音旗下产品
因为和飞书妙记的产品线不一样,一个是辅助会议记录,一个是为了降低用户发布抖音门槛,所以决定了两款产品未来的收费机制可能会不一样(剪映可能会一直免费下去,毕竟其已经区分了普通版和专业版)

之前还需要把音视频传到手机APP上进行字幕生成,现在也可以在Windows版剪映上进行操作了(实测目前网页版还不能进行此操作):https://www.capcut.cn/
使用方法也很简单,打开软件点击 » 开始创作,把音视频文件拖入到素材库 » 再将音视频拖入到剪辑轨道
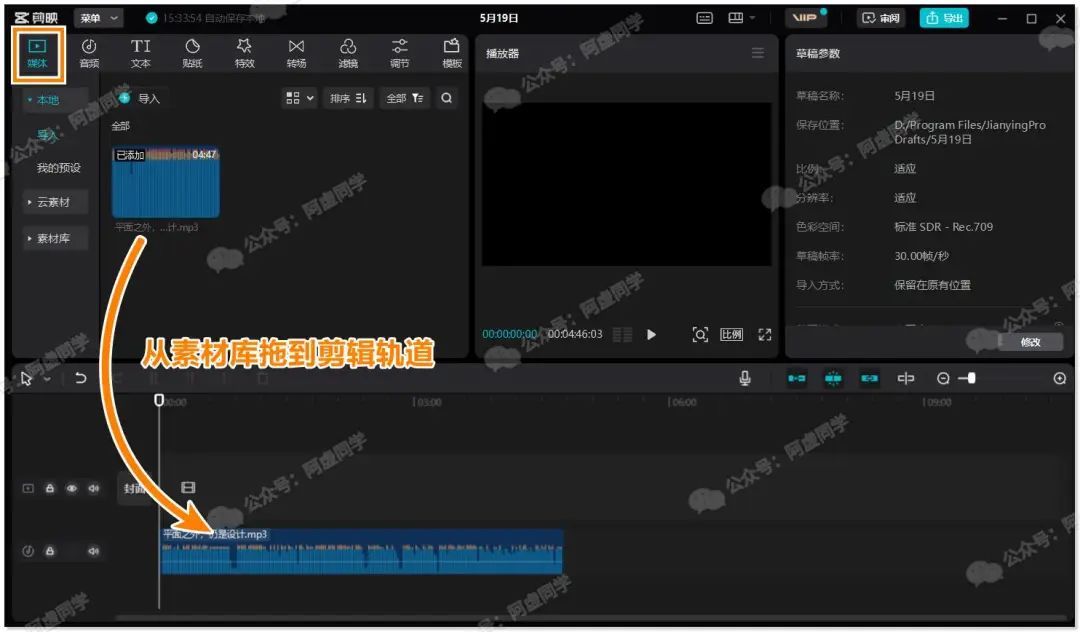
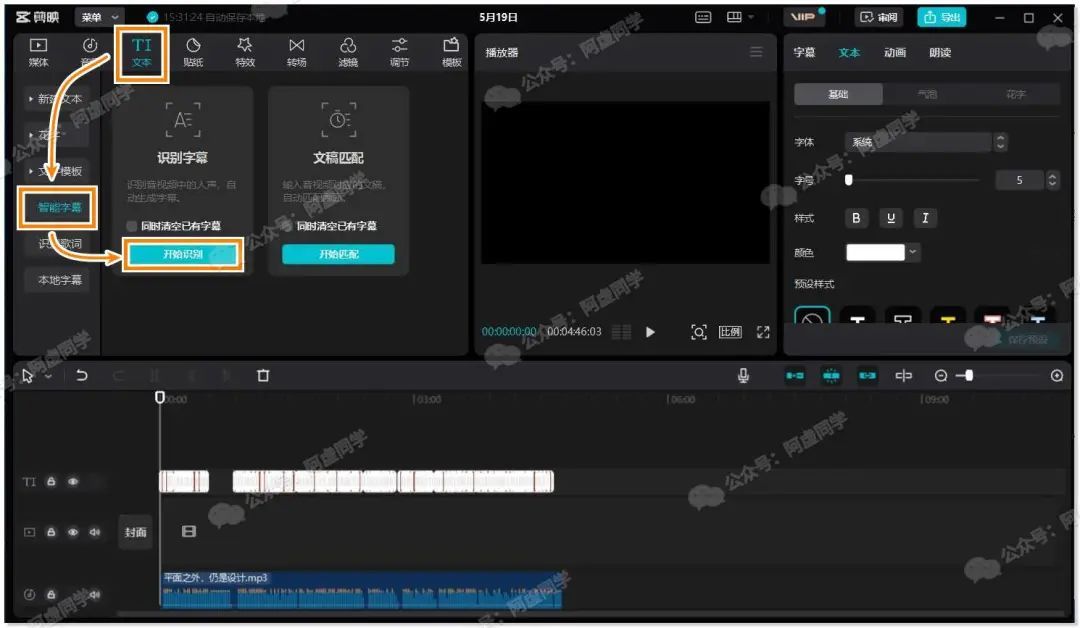
然后切换到文本功能,点击智能字幕,再点击开始识别,即可轻松进行语音识别了(最大支持 2 小时且不限次数使用)

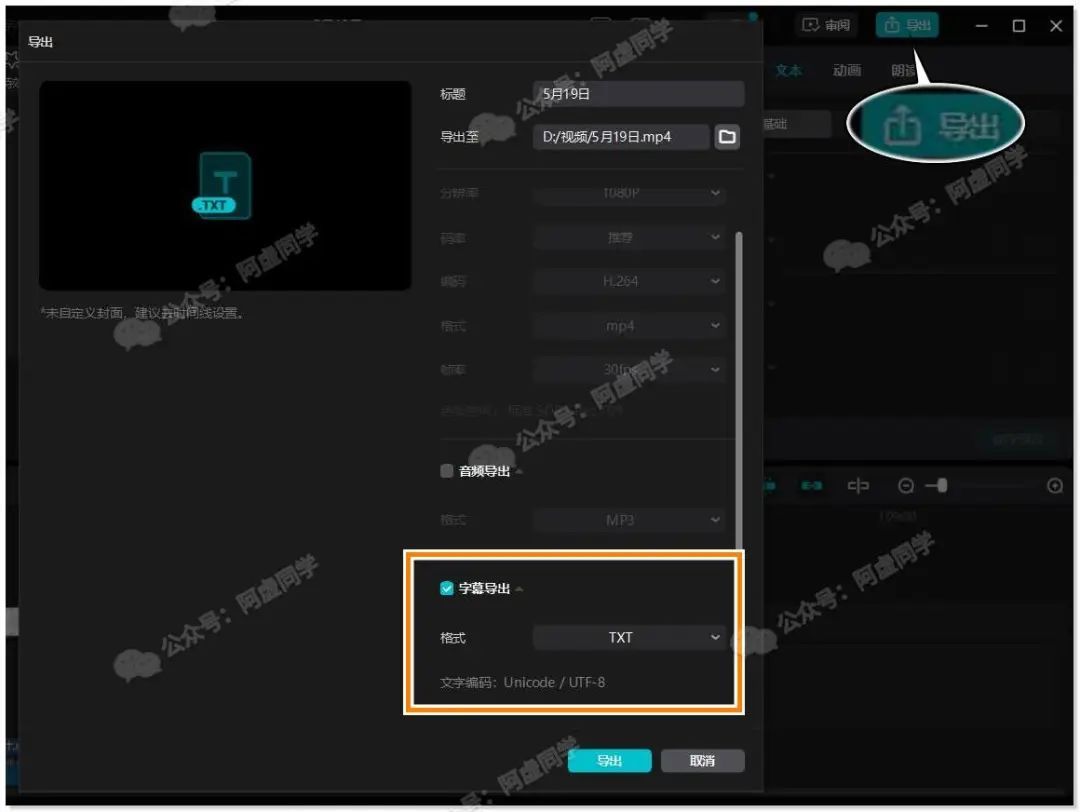
转换完成之后我们在右上角就能进行导出,可以仅保存字幕文件为 TXT 或者 SRT 文件
5
同花顺
5.1
悦录(网页/安卓/iOS)
地址:http://www.voiceclub.cn/
悦录是早在前几年阿虚就有补充推荐的免费 AI 语音转文字工具,实际是浙江核新同花顺网络信息股份有限公司(成立于1995年,于2009年在深交所上市,是国内第一家互联网金融信息服务行业上市公司)旗下产品
时至如今依然每日可免费转换 3 个小时的普通话,200小时音频的云端存储空间(相当于云盘),另网站和APP均支持导入wav、m4a、aac、mp3、amr、wma 等音频格式和 mp4、3GP、mkv、flv、mov、wmv、mxf、avi 等视频格式(单个音视频文件限制<500M)
同时支持区分说话人,还对金融财经、科技领域的音频有进一步的识别支持,并且支持提前输入音视频内的关键词来提高识别准确率
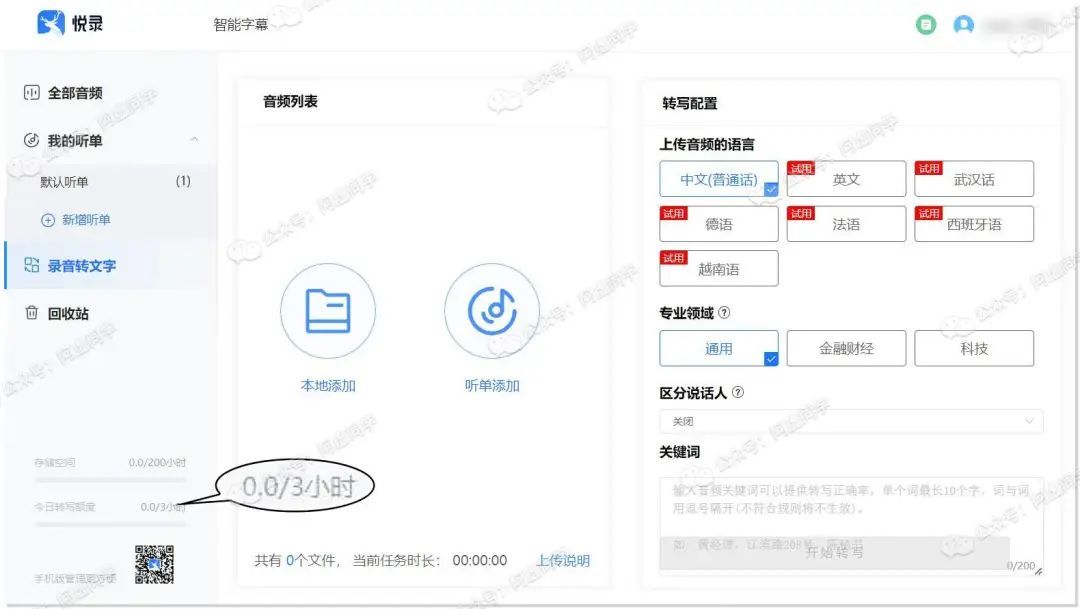
识别完之后可以在线查看,可以导出为 word 或者 txt,同时可以自行选择带不带时间戳
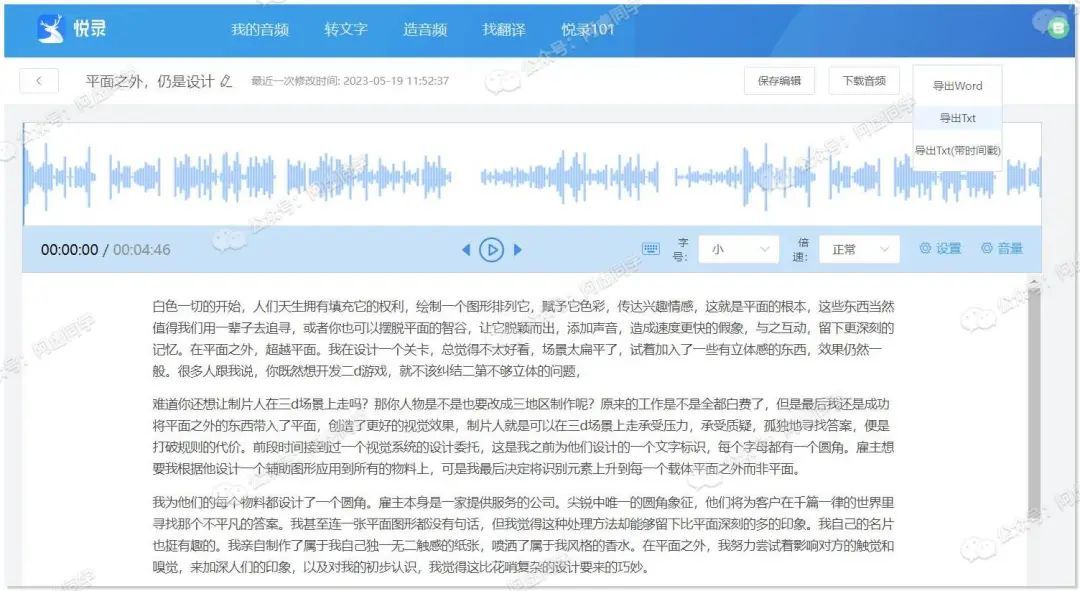
虽然不支持实时语音识别,但可以通过APP录音之后快速进行识别转换

6
百度
6.1
百度飞桨 PaddleSpeech(Win)
地址:https://github.com/PaddlePaddle/PaddleSpeech
既然网易、腾讯都介绍了,人工智能这块又怎么能少的了国内最早在此领域发力的百度?
早在2017年5月,百度飞浆就开源了旗下语音方向的模型库——PaddleSpeech
模型库有什么用呢?之前研究过「AI 绘画」的小伙伴应该都明白,AI 之所以能理解人类的意思,实际都是靠不断喂数据+反复匹配来提高吻合率的——AI 语音识别这一块也是一样
简单来说,根据百度飞桨官方文档搭建运行环境、安装依赖、下载模型库、编译源码之后,我们就能在本地离线进行语言识别了——不过自然这对90%的人来说都太难了
公众号@万能君的软件库基于 PaddleSpeech 开发了普通人也能一键使用的语音转文字工具,最关键的是可以离线无限次使用!

考虑到兼容性,目前的版本仅支持 CPU 转换,所以速度确实慢些⚠️(测试 R5-3600 的 CPU 一分钟音频转换时长30s,而测试 RTX 2060 显卡仅需 3s),仅支持Windows 64位系统
不过这个软件因为考虑到硬件方面的差异,对音频做了切分(每个切分片段时长 1 分钟),所以会影响一些句子的识别
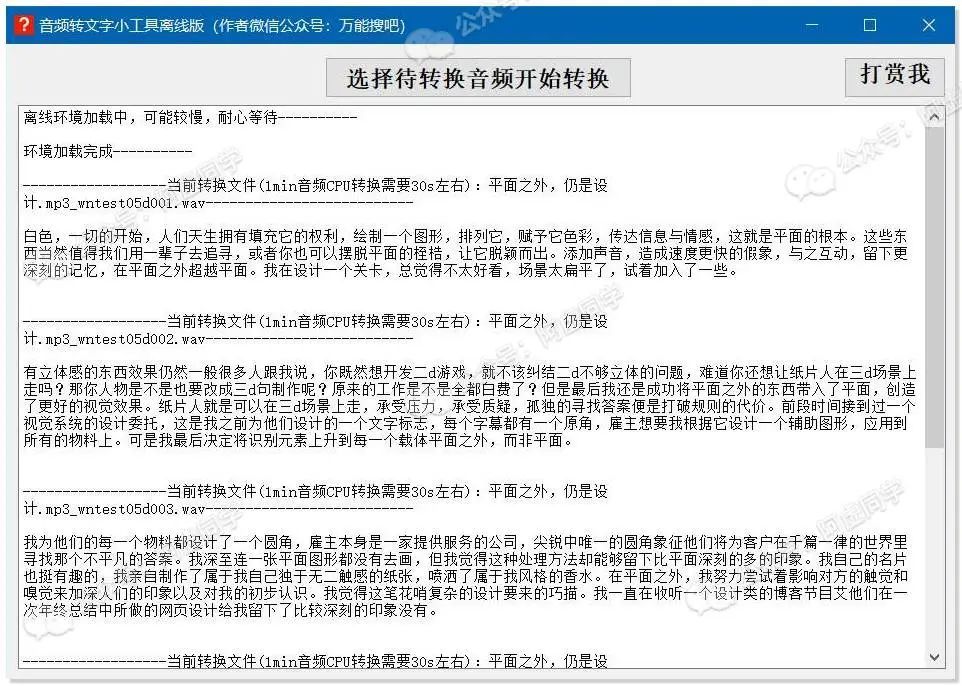
最终转换结果的话,会自动保存为软件目录的「音频转换结果」文件夹下的 txt 文件
这款软件你可以到原作者公众号下载,为防失效阿虚也做了搬运,在阿虚公众号后台,发送以下关键词,就可以得到不限速下载地址了:
“
语音转文字
”
7
OpenAI
大家都知道 ChatGPT 是 OpenAI 公司训练出来的大型语言模型,而其训练的模型其实远不止此
去年年底,OpenAI 开源了其经过 68 万小时多语言(99种)数据进行训练得出的大规模的语音识别模型——Whipser:https://github.com/openai/whisper
在现如今的综合离线的语音识别工具中,他应该是目前最好的选择!
当然,只有预训练模型我们是无法使用的,OpenAI 官方的部署运行方法对于多数人来说也是过于复杂,但好在已经有开发者为我们一般人开发了带界面的软件,只需要下载软件+再导入 Whipser 模型即可使用了

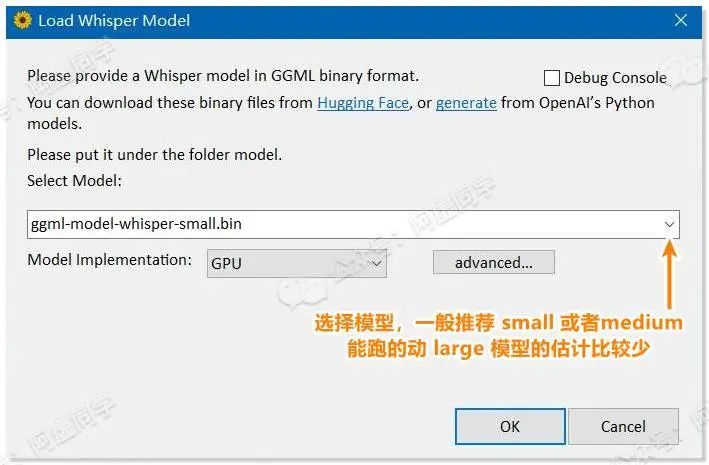
为应对不同的语音转录需求,Whipser 一共推出了 tiny、base、small、medium、large 5档模型,具体自己电脑能跑的动哪个模型得看显卡性能
同时为了方便理解,下面的相对速度用秒数表示(不代表实际时间),在相同的硬件条件下,处理音频所需时间
模型大小所需显存相对速度tiny39 M~1 GB32秒base74 M~1 GB16秒small244 M~2 GB6秒medium769 M~5 GB2秒large1550 M~10 GB1秒
<<左右滑动查看表格>>
由于 Whisper 的中文数据较少,如果转录的音频是中文,那么至少要用到 medium 模型,才能保证绝大多数正确
7.1
WhisperDesktop(Win)
Github地址:https://github.com/sakura6264/WhisperDesktop
如果你访问Github困难,建议了解《2022 Github加速访问教程》
下载 WhisperDesktop 后,将 Whipser 模型文件放入软件的 model 文件夹中,运行软件会让先让你选择模型,反正就是根据自己电脑性能能跑 large 就 large,不能就依次 medium、small…往下(当然如果你的音频太长,还得自己考虑处理时间)
不过由于 WhisperDesktop 支持 GPU 硬解,转录速度还是非常快的,阿虚测试 4 分多钟的音频,使用 medium 模型,几十秒就处理好了
为了方便下载,我已经将模型文件搬运到了国内的高速下载网盘,关注微信公众号:阿虚同学,发送以下关键词,后台即会回复下载地址了:
“
语音转文字
”
7.2
Buzz(Win/Mac/Linux)
Github地址:https://github.com/chidiwilliams/buzz
如果你访问Github困难,建议了解《2022 Github加速访问教程》
能用 WhisperDesktop 自然最好,如果你是 Mac 或者 Linux 系统,还有另一款带 GUI 界面的开源 Whipser 调用软件可供选择的——Buzz
缺点就是由于 Buzz 目前还不支持 GPU 硬解,只能使用 CPU 硬解,所以处理速度会慢很多!
Buzz 安装运行后会自动下载 .pt 格式的模型文件,但由于资源在国外下载速度较慢,阿虚建议是提前下好模型文件(公众号后台有提供),然后放在指定的文件夹,这样就能直接运行软件了:
Windows:C:\Users<你的用户名>.cache\whisper
Mac:~/.cache/whisper

运行软件之后的使用就非常简单了,在左上角导入音频,然后选择模型、语言、输出文件格式,最后点击 Run 即可

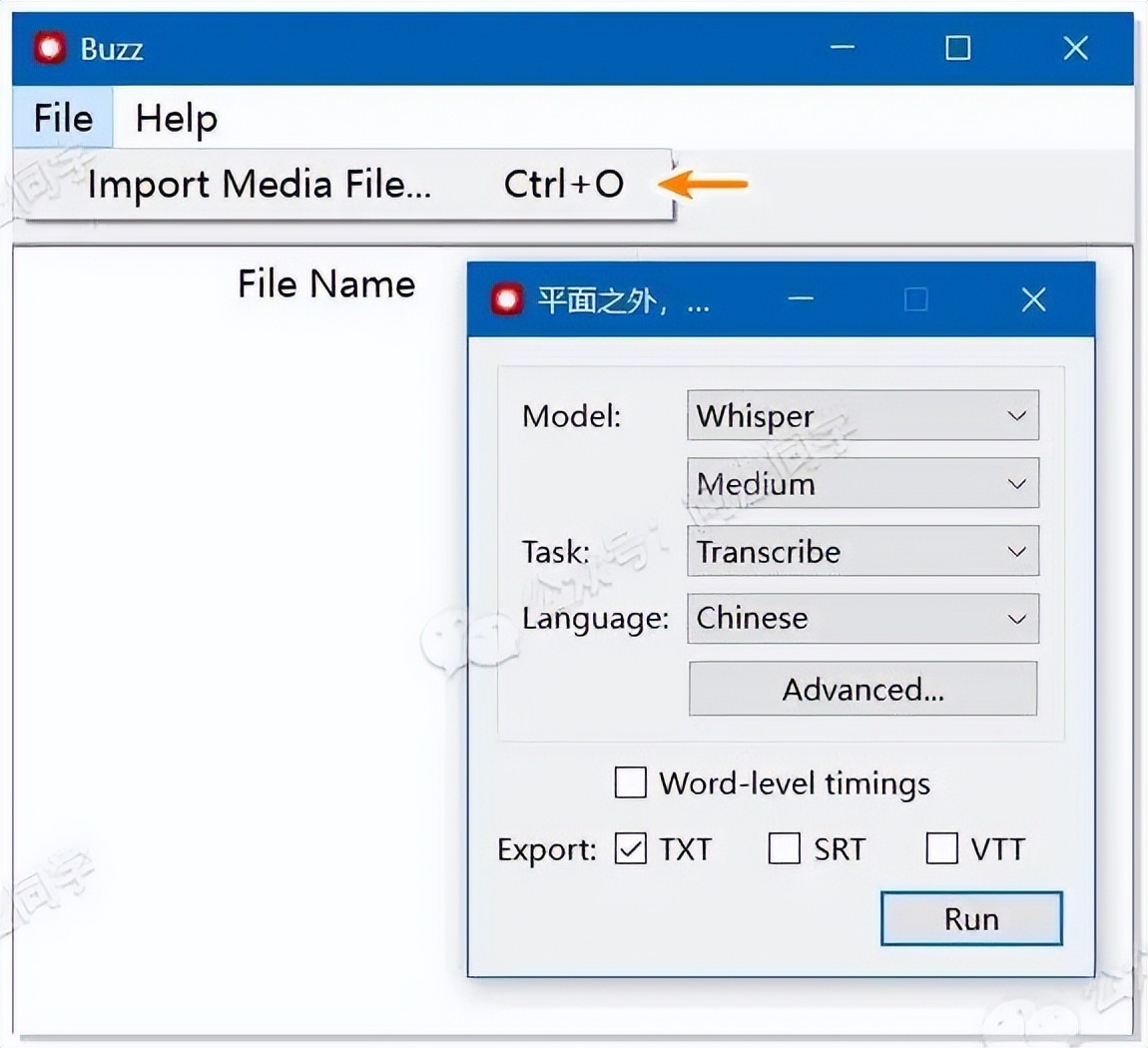
耐心等待转换完之后,点击下图的按钮(或者按快捷键Ctrl+E),就能打开识别结果导出为TXT了
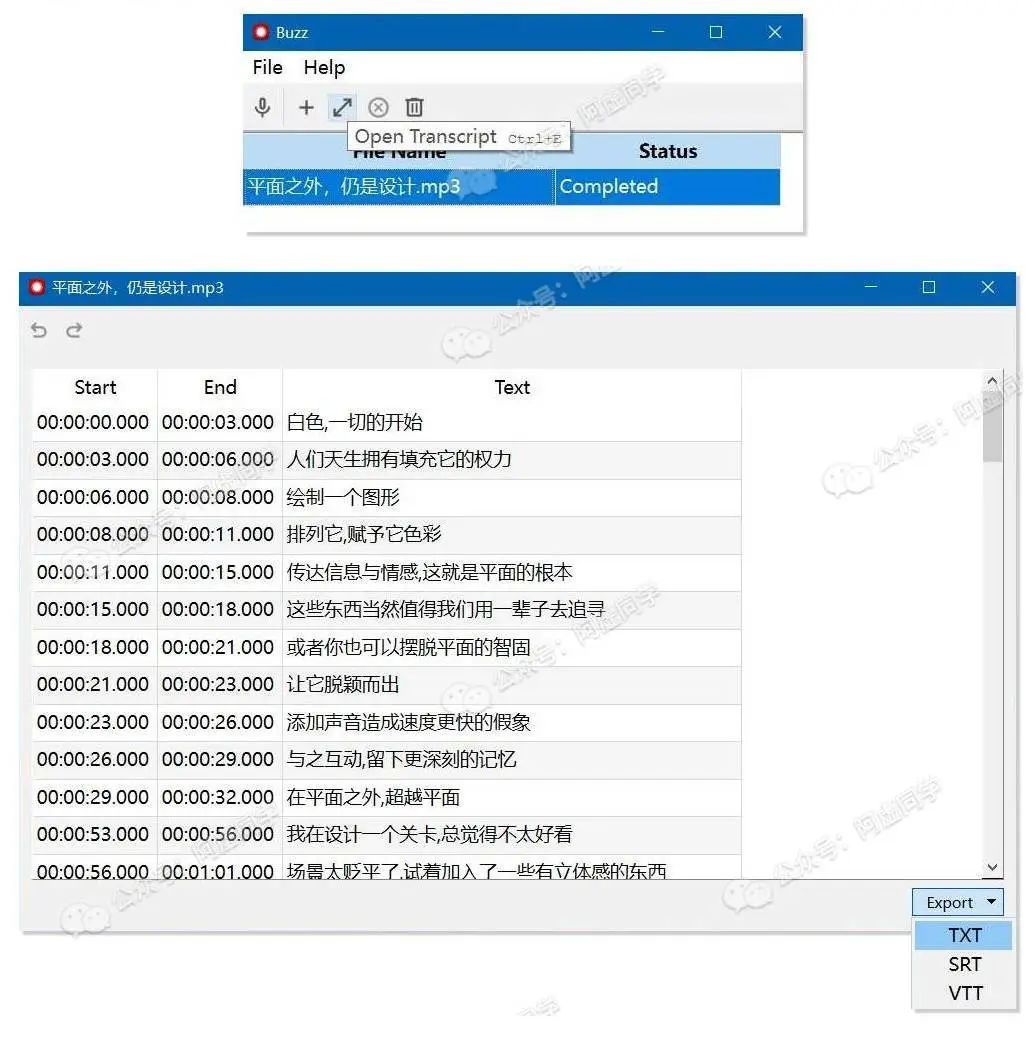
PS:Buzz 还有个问题是导出的 TXT 文件没有换行,需要你把文本复制到 word 利用 Ctrl+H 将其中的空格都替换为 ^p 才能实现换行
阿虚这里将 Buzz 的模型文件搬运到了国内的高速下载网盘,可以关注微信公众号:阿虚同学,发送以下关键词,后台即会回复下载地址了:
“
语音转文字
”

今天介绍了来自百度、腾讯、网易、阿里巴巴、字节跳动、同花顺、OpenAI 的免费语音识别服务,多虽然多,但具体识别质量才是最关键的
而最关键的内容肯定是留到最后啦,阿虚找了2段音频做测试,得出了以下结果:
原文传达信息与情感摆脱平面的桎梏2D不够立体纸片人就是可以在3D场景上走尖锐中唯一的圆角收听一个设计类的播客节目小岛秀夫合金装备打破了次元壁皆可设计网易:网易见外传达兴趣与情感摆脱平面的质骨二d不顾立体纸片人就是可以在三d场景上走尖锐中唯一的远角收听一个设计类的博客节目小岛修复合金装备打破了次元币皆可设计网易:有道云笔记传达信息与情感摆脱平面的智慧二d不可立体纸片人就是可以在三d场景上走监狱中唯一的圆角收听一个设计类的播客节目小岛修复核心装备打破了次元壁皆可设计腾讯云?传达信息与情感摆脱平面的桎梏2D不够立体纸片人就是可以在3D场景上走尖锐中唯一的圆角收听一个设计类的博客节目小岛秀夫核心装备打破了次元壁杰克设计阿里云?传达信息与情感摆脱平面的桎梏2D不够立体纸片人就是可以在3D场景上走尖锐中唯一的圆角收听一个设计类的播客节目小岛秀夫合金装备打破了次元壁皆可设计字节跳动:飞书妙记?传达信息与情感摆脱平面的桎梏2D 不够立体只骗人就是可以在 3D 场景上走尖锐中唯一的圆角收听一个设计类的博客节目小岛修复合金装备打破了次元壁皆可设计字节跳动:剪映传达信息与情感摆脱平面的质股2D不够立体只骗人就是可以在3D场景上走尖锐中唯一的圆角收听一个设计类的波克节目小岛修复合金装备打破了次元币皆可涉及同花顺:悦录传达兴趣情感摆脱平面的智谷二第不够立体制片人就是可以在三d场景上走尖锐中唯一的圆角收听一个设计类的博客节目小岛修复核心装备打破了次元比接口设计百度:百度飞桨?传达信息与情感摆脱平面的桎梏二d不够立体纸片人就是可以在三d场景上走尖锐中唯一的圆角收听一个设计类的博客节目小岛秀夫核心装备打破了次元币皆可设计OpenAI:Whisper?传达信息与情感摆脱平面的智固2D不够立体纸片人就是可以在3D场景上走尖锐中唯一的圆角收听一个设计类的播客节目小岛秀夫合金装备打破了次元币皆可设计
<<左右滑动查看表格>>
上述测试音频来源于 @oooooohmygosh 的《平面之外,仍是设计》这期视频:https://www.bilibili.com/video/BV1SA41187Ms/
原文碎片时间坐下来写写脚本布满巧克力味道哪些实际意义呢氪金手游大脑前额叶皮质睡前读一页多巴胺、内啡肽网易:网易见外随便时间坐下来写写脚本不满巧克力味道哪些实际意能刻金手游大脑前额液皮质睡前读一页多巴胺,内贝泰网易:有道云笔记睡眠时间坐下来写写脚本不满巧克力味道哪些实际意义呢合金手游大脑前熬夜皮质睡前读一页多巴胺、那边太腾讯云?碎片时间坐下来写写脚本布满巧克力味道哪些实际意义呢氪金手游大脑前额叶皮质睡前读一页多巴胺、内啡肽阿里云?碎片时间坐下来写写脚本布满巧克力味道哪些实际意义呢氪金手游大脑前额叶皮质睡前读一页多巴胺、内啡肽字节跳动:飞书妙记?碎片时间坐下来写写脚本布满巧克力味道哪些实际意义呢氪金手游大脑前额叶皮滞睡前读一夜多巴胺、内悲态字节跳动:剪映?碎片时间坐下来歇歇脚本布满巧克力味道哪些实际意义呢氪金手游大脑前额叶皮质睡前读一夜多巴胺、内啡肽同花顺:悦录碎片时间坐下来写写脚本不满巧克力味道哪些实际意能克金手游大脑前额叶皮滞睡前读一夜多巴胺、内胚肽百度:百度飞桨碎片时间坐下来写写脚本不满巧克力味道哪些实际意呢氪金手游大脑前额夜皮质睡前读一夜多巴胺、内胚肽OpenAI:Whisper碎片时间坐下来写写脚本不满巧克力味道有哪些实际意义呢课金手游大脑前额叶皮质睡前读一夜多巴胺、内胚胎
<<左右滑动查看表格>>
上述测试音频来源于 @帅soserious 的《这个习惯改变了我的人生》这期视频:https://v.douyin.com/UAhc2om/
如果综合阿虚测试的这2段音频:
阿里云应该是目前独一档的,针对各种固有名词、网络词语,甚至名人人名都能实现准确识别,整体错误相当之少
腾讯云、字节跳动的飞书妙记&剪映、百度飞桨、OpenAI 的 Whisper 则表现时好时坏,算是第二梯队吧
网易见外、网易有道云笔记、同花顺悦录属于最拉胯一梯队,相较之下不推荐使用
不过由于阿里云配置相当麻烦且每天仅有 2 小时的语音识别免费额度,以后还不保证能一直提供免费额度,那可以免费、离线、无限次使用的百度飞桨、OpenAI:Whisper 就拥有相当大的优势了
总而言之,今天介绍的语音识别工具都是免费的,大家完全可以综合一起使用,选一个最能满足自己需求的












评论前必须登录!
立即登录 注册