浏览网页经常会遇到一些无法复制的文档,或者偶尔需要复制某些图片上的文字,你们一般会怎么解决呢?
这种情况一般来说最简单,最直接的方式还是使用 OCR 软件比较好,毕竟 OCR 是一种非常知名又常见的文字识别技术。
即使是腾讯这种大公司,也可以随处见到 OCR 的身影,就比如微信和 QQ 就早已内置了 OCR 文字识别技术。
使用微信、QQ 截图或者打开某张图片之后,就能够看到「翻译」和「提取文字」这样的功能。

这里腾讯就借用了 OCR 技术,提取文字和翻译其实就是通过 OCR 识别出图片上的文字信息,然后翻译成其它语言。
如果没有特殊需要,在一定程度上,微信 QQ 已经足够我们使用,无非就是麻烦点,每次使用之前都需要开启聊天软件。
但是这种方式也不是万能的,可以使用的前提是存在网路,如果断网,所有功能也就全部都成了摆设。
所以个人建议还是准备一款可以离线使用的 OCR 软件比较好,随时以备不时之需。
在此之前,我们分享过几款可用的免费 OCR 软件,有些需要网络,有些则支持离线功能,不管哪款,几乎都基于开源的 PaddleOCR。
在不同开发者的二次开发之下,各款又各有特色,功能偏向也各不相同。
PearOCR(点击跳转)主打网页端 OCR 识别,无需安装任何软件,只需要上传图片至到网站即可识别,无法做到离线使用,可能存在一定隐私安全风险。

Umi-OCR(点击跳转) 绿色免安装,支持离线功能,支持批量识别,支持截图和本地图片识别,如果安装语言识别包,还可以识别更多语言。

eSearch(点击跳转)虽然也支持 OCR 识别,但是功能更加全面,还支持截图、录屏、截图搜索等多种功能,简直可以称得上全能型神器!

那么今天再给大家补充一款最新出品,仍基于 PaddleOCR 开发的第三方 OCR 软件——OcrHelper。
这款软件仍然主打离线和绿色免安装,但因为软件内置文字识别库,所以体积方面偏大一点,压缩包就有 160M,解压之后的文件夹更是达到了 400 多 M。
OcrHelper 中文名为文字识别助手,软件比较简单,不需要用户手动截图,左侧是识别区,右侧是文字区。
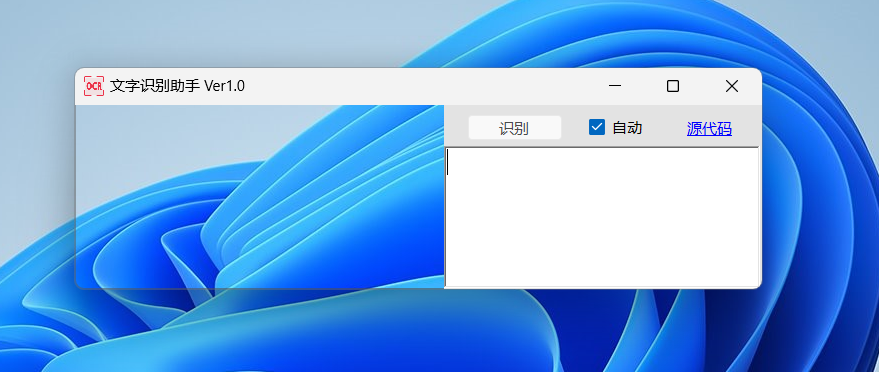
也不需要我们去截图什么的,识别区扫过的地方,文字识别助手即可自动识别出内容。

如果不需要自动识别,也可以关闭自动识别功能,这样每次识别都需要点击「识别」按钮。
OcrHelper 可以从图片中识别出汉字,英文,数字,准确率高达 95%,目前软件已经开源,仅支持 Windows7 及以上 64 位系统。
软件适用多种场合,比如直播间弹幕识别,聊天识别、社交群,私域流量消息管理、pdf 以及不可复制场景文字内容提取等等。
不过 OcrHelper 也有其不足之处,首先是自动识别出的内容无法复制,这是一个重大缺陷,也可能是 BUG,目前 OcrHelper 只发布了首个 v1.0 版本,只希望作者后续更新能加以改善。
其次就是特别占用电脑 CPU,开启 OcrHelper 一分钟之后,电脑散热器会呼呼作响,要是再同时开启几款软件,只怕就得死机了!
开源地址:
https://github.com/xksoft/OcrHelper
网盘下载:
https://www.123pan.com/s/6zVRVv-Mfmmd.html










评论前必须登录!
立即登录 注册